Vector embeddings in search
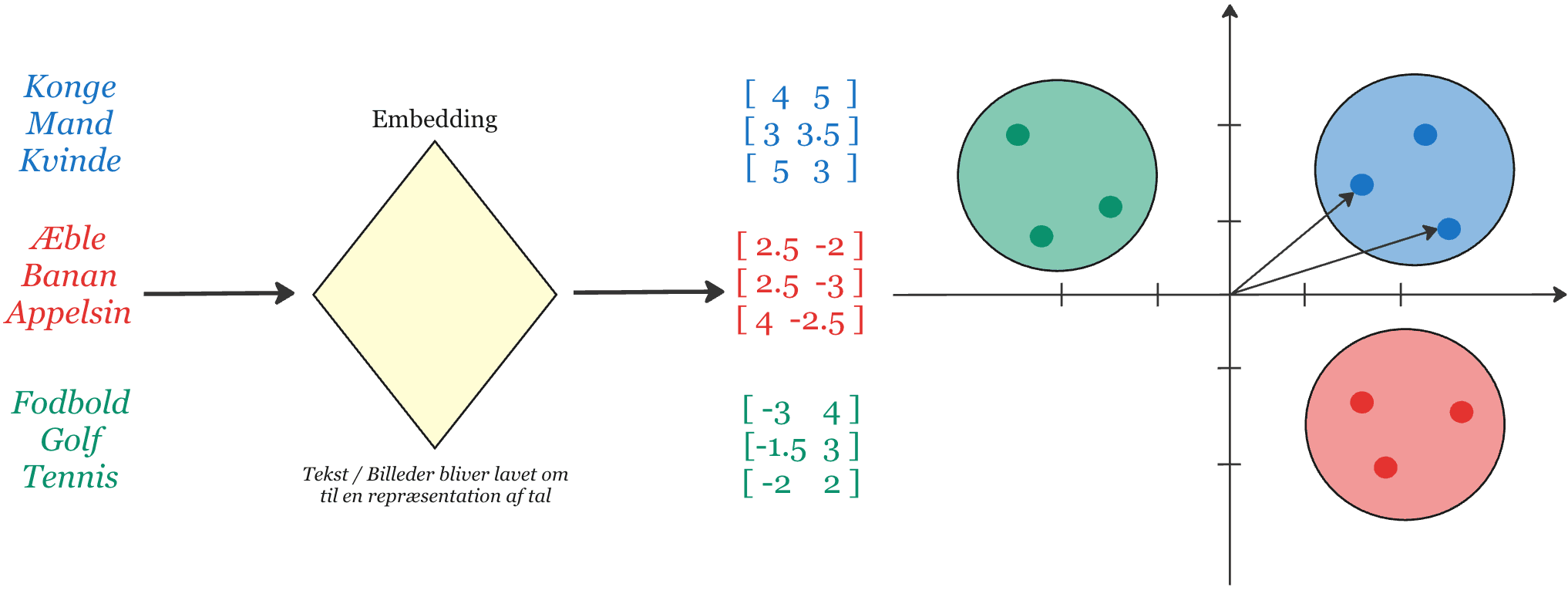
Embeddings are the core of our search system. Text and data are converted into vectors that can be compared efficiently and semantically.
Core capabilities
- Documents and queries are embedded into the same semantic space
- Retrieval finds relevant evidence from meaning — not only keywords
- Re-ranking prioritizes the strongest sources before generation
- Results are returned with summaries and explicit grounding
Why AI cannot read your data — and how we solve it
Nearly all enterprise information is created for humans: Word documents, PDFs, emails, websites, spreadsheets. It is formatted for eyes, not algorithms. An AI model cannot simply open a SharePoint library and understand the content — it lacks structure, context, and access rules. That is exactly the problem our system solves. We transform your human-readable data into a machine-readable foundation, so AI can search, understand, and answer based on your actual documents — not general knowledge from the internet.
From human format to machine-readable foundation
The world's data is designed for screens and paper. But AI agents need structured, machine-friendly input to act precisely. Major technology companies like Google are already bridging this gap: their new tools deliver structured JSON output and standardized protocols (MCP) that let AI agents access systems directly. We apply the same principle to your internal data: documents are converted to vector embeddings — numerical representations that place text in a semantic space where AI can search by meaning, not just keywords.
Controlled retrieval eliminates hallucinations
Our RAG architecture (Retrieval-Augmented Generation) ensures AI only answers based on retrieved source material from your approved documents. The model does not invent answers — it finds them. If retrieval does not find sufficient evidence, the system abstains from answering. This makes output traceable, controllable, and audit-ready.
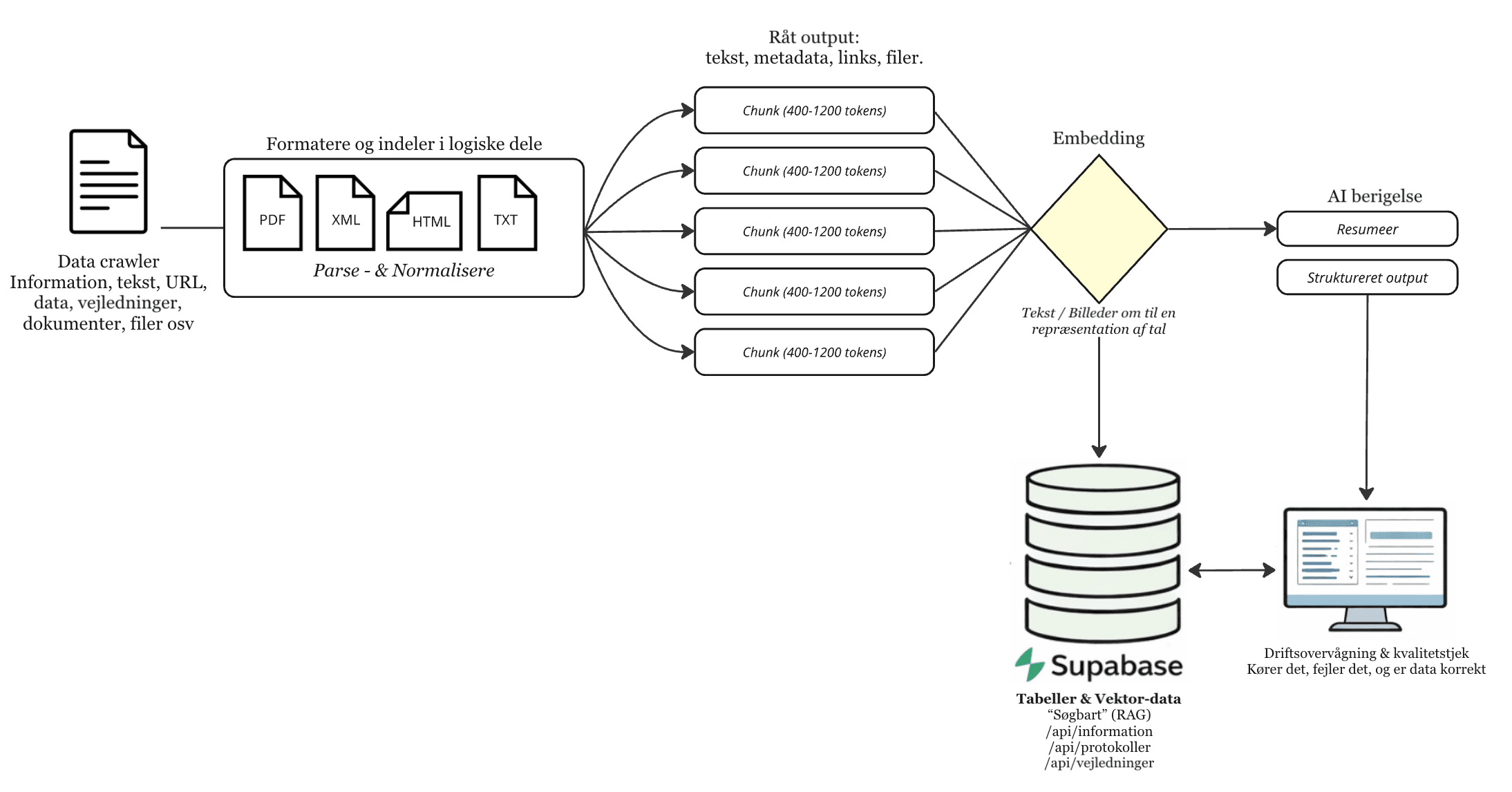
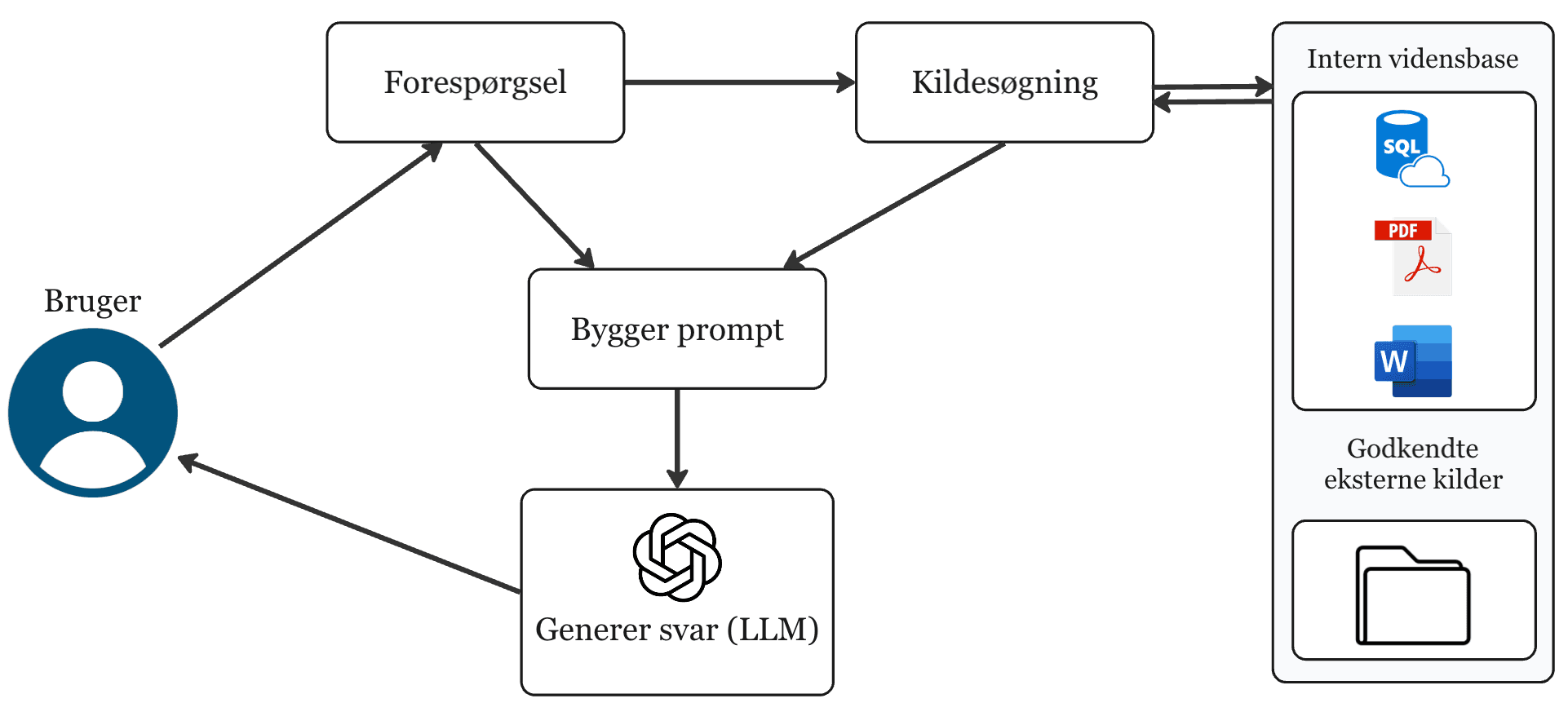
How the system works in practice
Your data becomes machine-readable
Documents from SharePoint, file drives, databases, and other sources are split into logical chunks and converted to vector embeddings. Each chunk is enriched with metadata — source, date, classification — and stored in a vector database ready for retrieval.
The query is analyzed and optimized
The user query is converted to the same vector format and enriched with context. The system expands the search to relevant variants, ensuring it finds the right answers regardless of phrasing.
The most relevant sources are retrieved
The system finds the chunks semantically closest to the query. Re-ranking prioritizes the strongest candidates, and filtering ensures only authorized and current sources are included.
Answer generated with source citations
The model generates an answer based exclusively on the retrieved sources. Output is delivered with clickable source references so the user can verify the evidence and continue working with documented information.
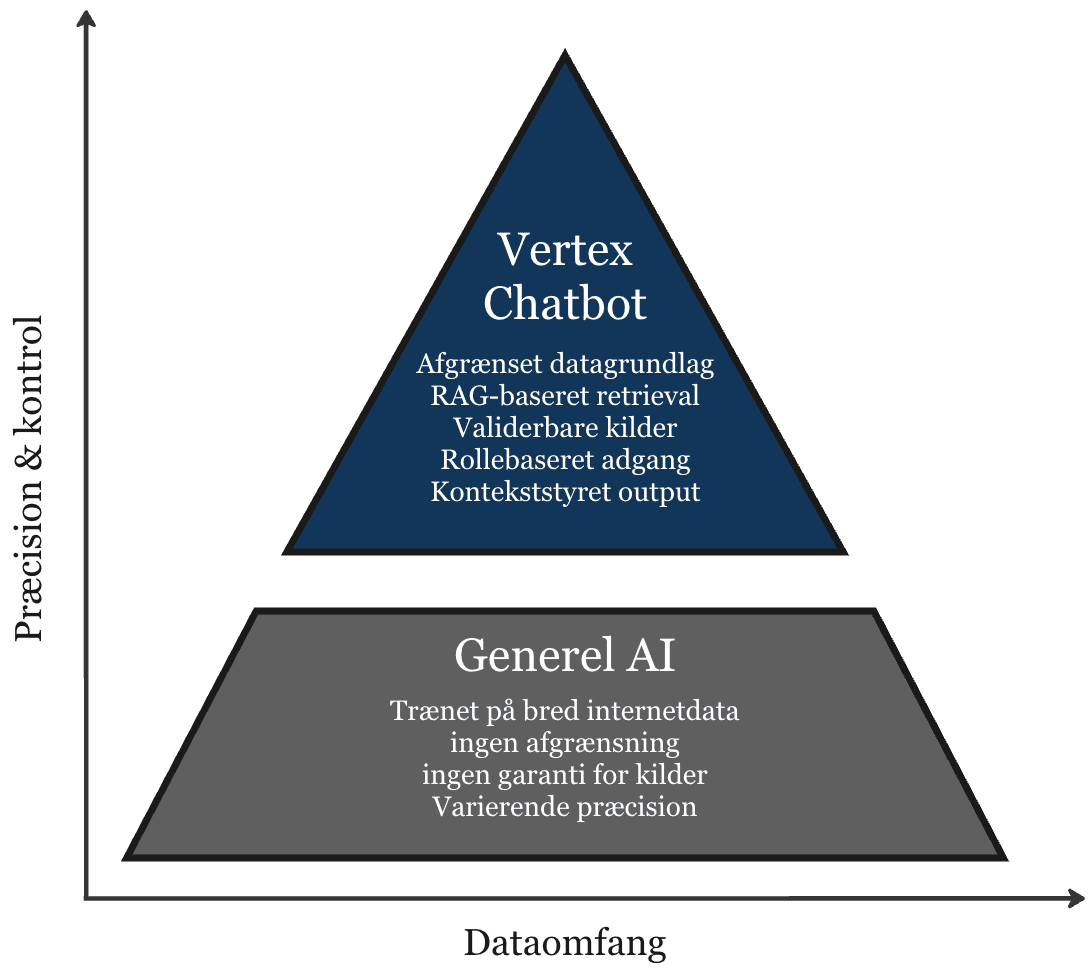
Domain-specific chatbot - built for controlled operations
An internal assistant that only answers from your approved data foundation. The system retrieves and prioritizes relevant material before generation, so outputs stay precise and controllable.
Core capabilities
- Source-grounded answers - with clear basis and references
- Access control - responses and data by role and entitlement
- Traceability - logging, decision trail, and audit-ready output
- Controlled answer logic and explicit instructions
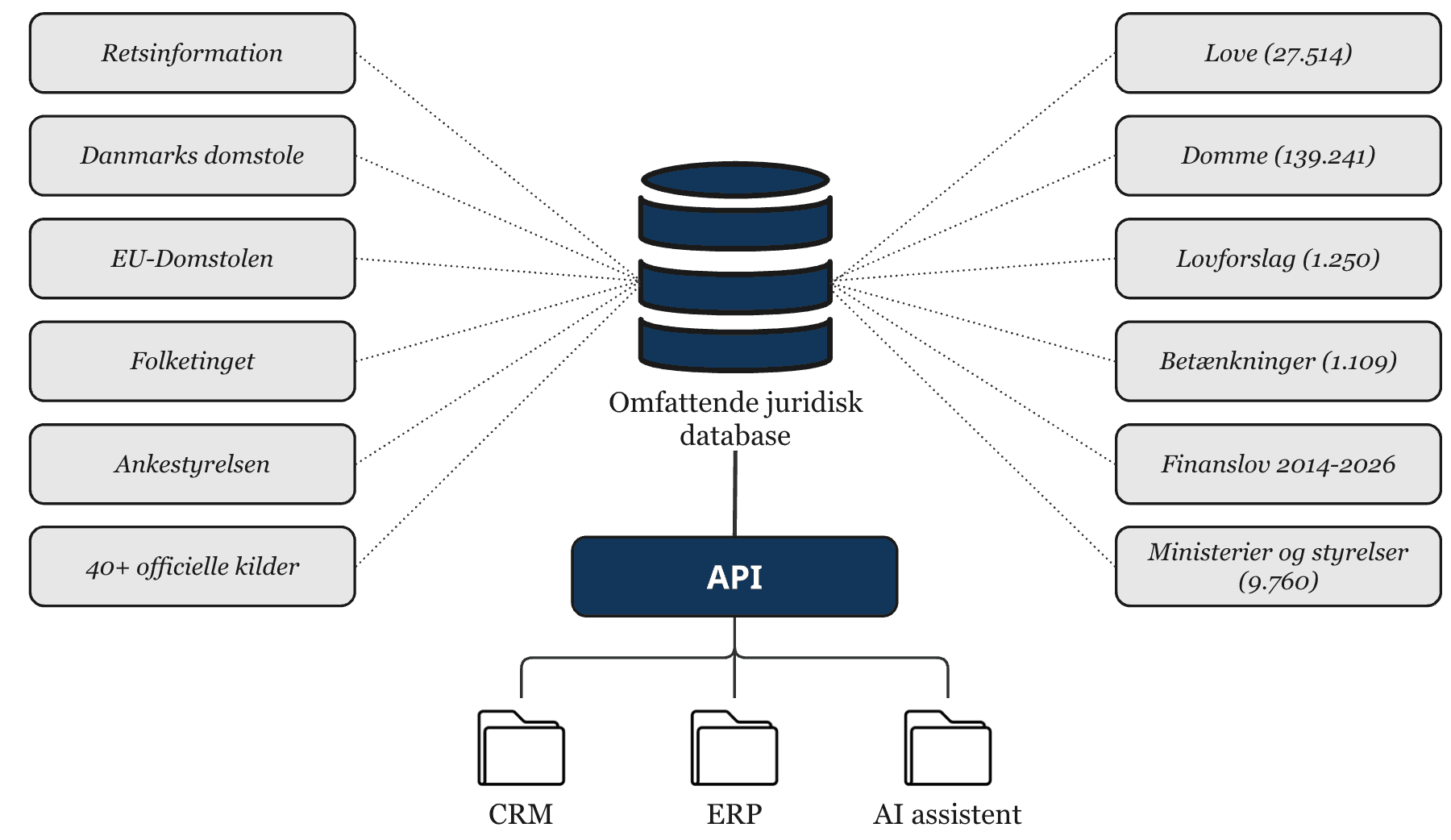
Comprehensive legal database
We maintain a comprehensive legal database with official sources, version-safe references, and citation-ready output. The database can be used in solutions built around Danish law and legal practice.
- • 27,514 laws (15,267 active, 12,247 historical)
- • 139,241 rulings and decisions
- • 1,250 new law proposals and 1,109 reports
- • 40+ official sources, including Retsinformation, Danish Courts, the EU Court of Justice, and Parliament
Microsoft integration - built on top of your existing setup
Our solutions are designed to work directly with your Microsoft environment. You do not need to replace systems, migrate data, or introduce new login structures. We add a controlled AI layer on top of what you already use.
That means your documents stay in SharePoint and OneDrive, your communication stays in Teams and Outlook, and access is managed through Microsoft Entra ID. Our platform acts as a governance and control layer between your data and the AI models.
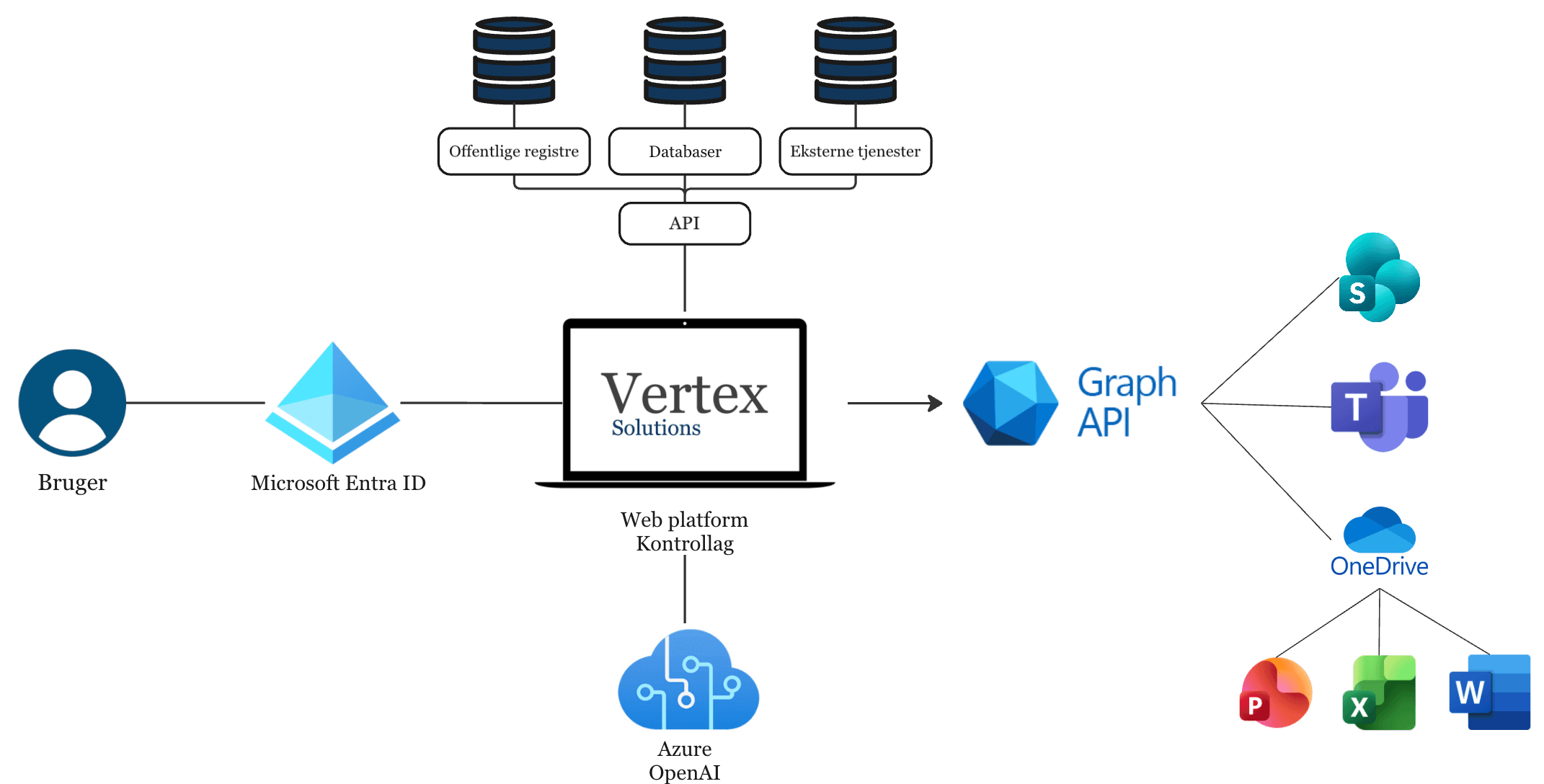
How the integration works in practice
- 01
Login via Microsoft Entra ID
Users sign in with the company's existing Microsoft login. Permissions and roles are carried over automatically.
- 02
Access through Microsoft Graph
The platform only retrieves data the user already has access to in SharePoint, Teams, or OneDrive. We do not bypass your permission model - we enforce it.
- 03
Controlled processing in the platform
Before data is sent to AI, the platform applies controls for:
- • Scoped data boundaries
- • Role-based access
- • Logging and traceability
- • Optional approval checkpoints
- 04
AI in your Azure environment
AI calls run through Azure OpenAI in your tenant. Data does not leave your Microsoft setup, and the model only receives the context explicitly provided by the platform.
What this means for your organization
- • No new login
- • No document migration
- • No parallel systems
- • Full respect for your permission model
- • Traceability and documentation for AI usage
Especially relevant for compliance-driven organizations
For organizations handling sensitive data or regulatory requirements, it is critical that AI does not run uncontrolled across the entire data estate. Our approach provides:
- • Scoped retrieval from approved sources
- • Transparent response logic
- • Role-based access
- • Documentable usage
- • Option for human approval in critical processes
This makes the solution suitable for law firms, public authorities, audit firms, and other knowledge organizations where precision and accountability are essential.
In short
We do not replace your Microsoft setup. We strengthen it.
The platform unifies identity (Entra ID), data (SharePoint, OneDrive, Teams), integration (Graph API), and AI (Azure OpenAI) in one controlled architecture where you keep ownership, governance, and visibility.