Vektorembeddings i søgning
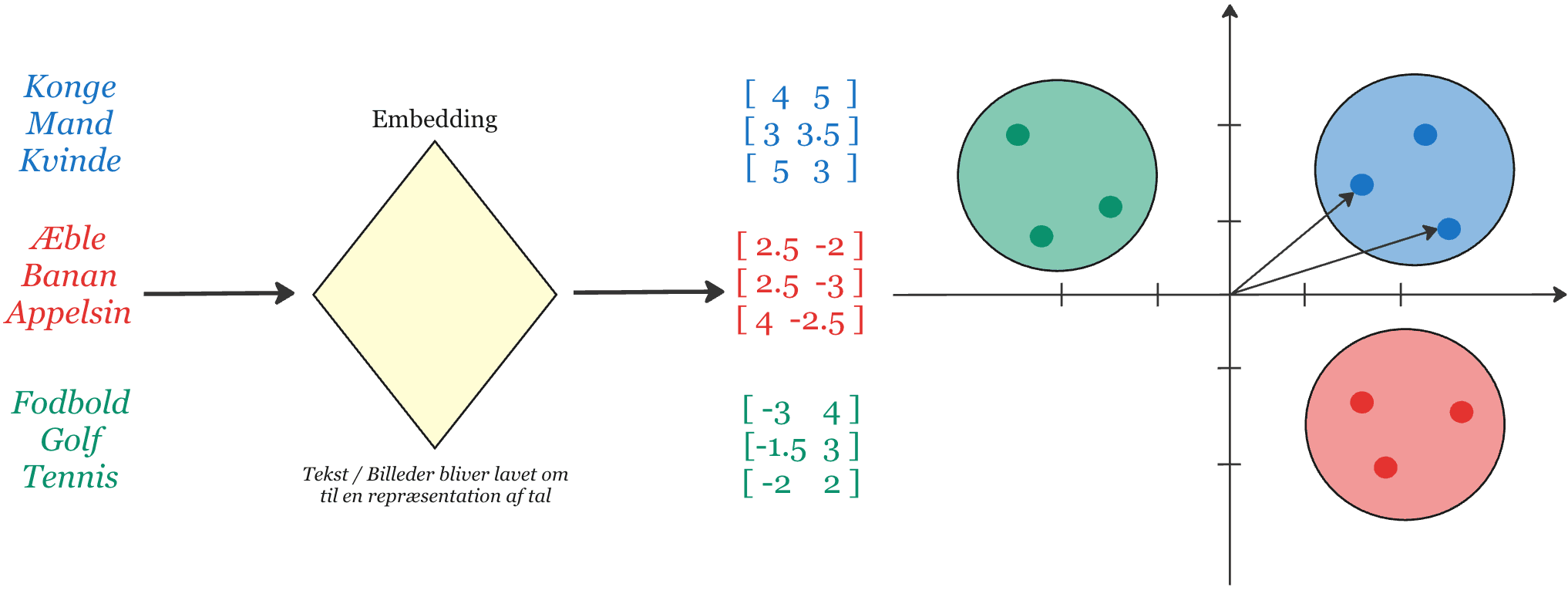
En embedding-model omsætter tekst til numeriske vektorer (lister af tal). I dette rum ligger dokumenter med lignende indhold tættere på hinanden, hvilket gør søgningen mere præcis selv ved variationer i formulering.
Kerneegenskaber
- Samme embedding-model bruges til både dokumenter og forespørgsler
- Relevans beregnes via vektorafstand (fx cosinus-lighed)
- Søgning matcher betydning, synonymer og omskrivninger - ikke kun nøgleord
- Omrangering prioriterer de stærkeste kilder, før svar genereres
- Resultater leveres med tydeligt grundlag og kildehenvisning
Hvorfor AI ikke kan læse jeres data — og hvordan vi løser det
Næsten al information i virksomheder er skabt til mennesker: Word-dokumenter, PDF'er, e-mails, hjemmesider, regneark. Det er formateret til øjne, ikke til algoritmer. En AI-model kan ikke bare åbne et SharePoint-bibliotek og forstå indholdet — den mangler struktur, kontekst og adgangsregler. Det er præcis det problem, vores system løser. Vi omdanner jeres menneskevenlige data til et maskinlæsbart grundlag, så AI kan søge, forstå og svare på baggrund af jeres faktiske dokumenter — ikke generel viden fra internettet.
Fra menneskeligt format til maskinlæsbart grundlag
Verdens data er designet til skærme og papir. Men AI-agenter har brug for struktureret, maskinvenligt input for at handle præcist. Store teknologivirksomheder som Google er allerede i gang med at bygge bro: deres nye værktøjer leverer struktureret JSON-output og standardiserede protokoller (MCP), der lader AI-agenter tilgå systemer direkte. Vi anvender samme princip på jeres interne data: dokumenter konverteres til vektorembeddings — numeriske repræsentationer, der placerer tekst i et semantisk rum, hvor AI kan søge på betydning, ikke kun nøgleord.
Kontrolleret søgning eliminerer hallucinationer
Vores RAG-arkitektur (Retrieval-Augmented Generation) sikrer, at AI kun svarer på baggrund af hentet kildemateriale fra jeres godkendte dokumenter. Modellen opfinder ikke svar — den finder dem. Hvis kildesøgningen ikke finder tilstrækkeligt grundlag, afstår systemet fra at svare. Det gør output sporbart, kontrollerbart og revisionsparat.
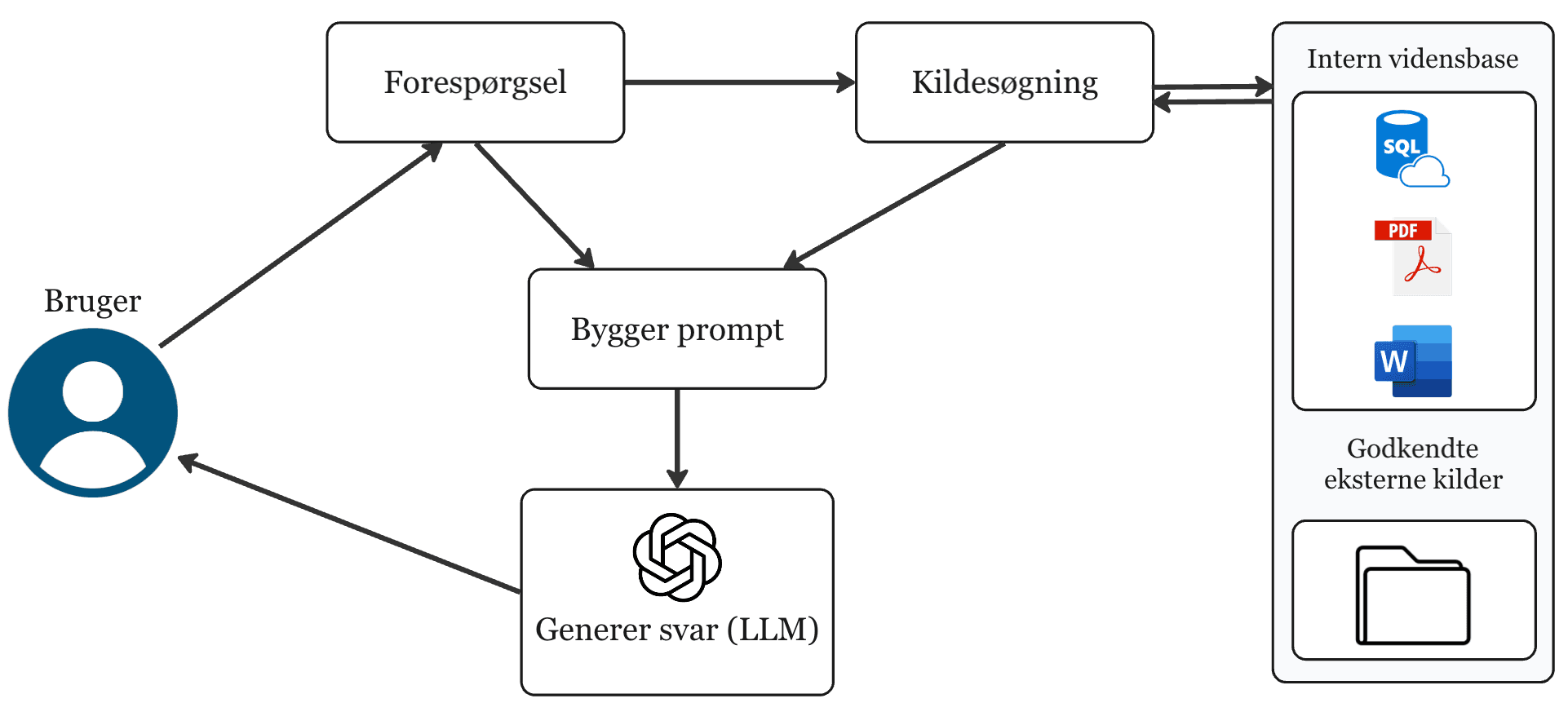
Sådan fungerer systemet
Jeres data gøres maskinlæsbart
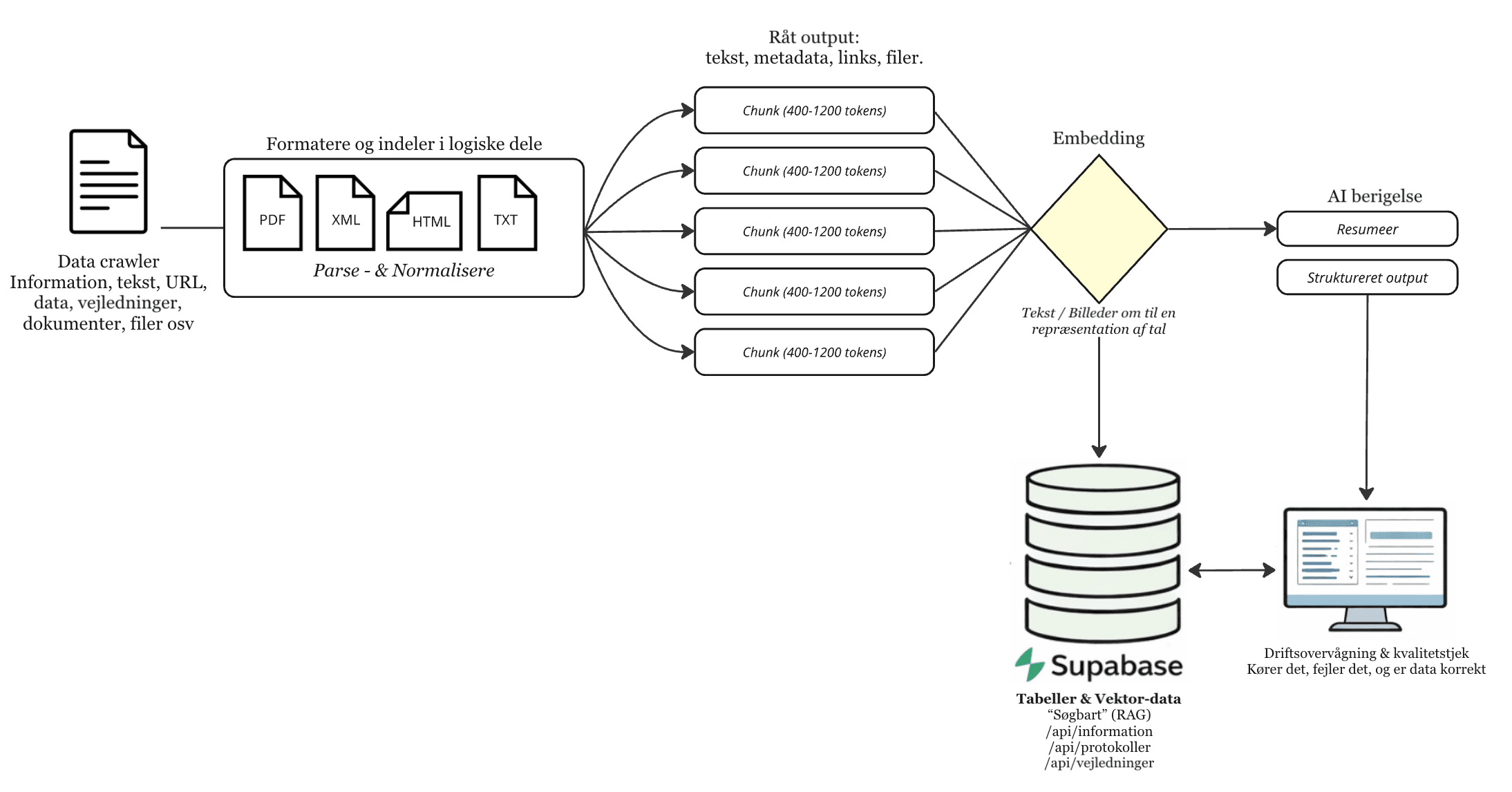
Dokumenter fra SharePoint, fildrev, databaser og andre kilder opdeles i logiske tekstblokke og konverteres til vektorembeddings. Hver blok beriges med metadata — kilde, dato, klassificering — og gemmes i en vektordatabase klar til søgning.
Spørgsmålet analyseres og optimeres
Brugerens forespørgsel omsættes til samme vektorformat og beriges med kontekst. Systemet udvider søgningen til relevante varianter, så det finder de rigtige svar uanset formulering.
De mest relevante kilder hentes frem
Systemet finder de tekstblokke, der ligger semantisk tættest på forespørgslen. Omrangering prioriterer de stærkeste kandidater, og filtrering sikrer, at kun autoriserede og aktuelle kilder indgår i grundlaget.
Svar genereres med kildeangivelse
Modellen genererer et svar udelukkende baseret på de hentede kilder. Svar leveres med klikbare kildehenvisninger, så brugeren kan verificere grundlaget og arbejde videre med dokumenteret information.
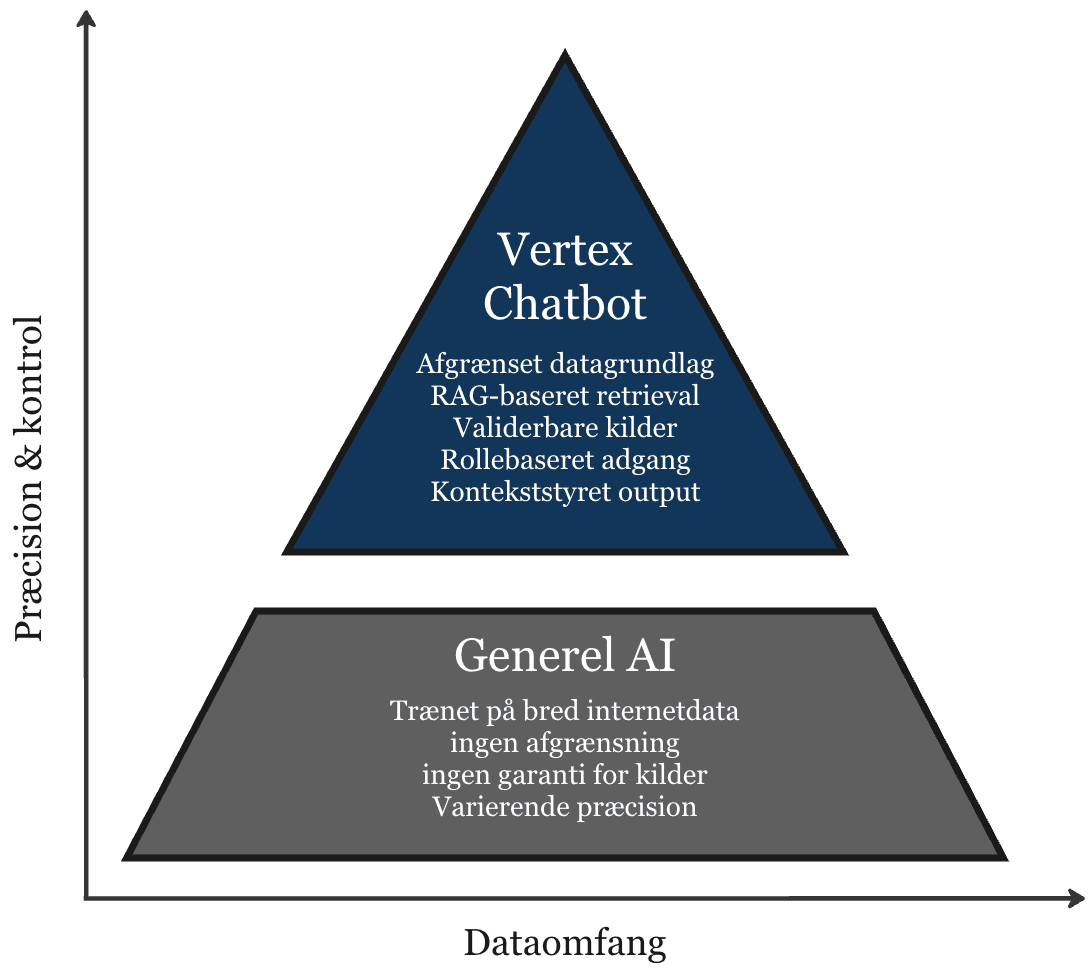
Domænespecifik chatbot - bygget til kontrolleret drift
En intern assistent, der kun svarer ud fra godkendt datagrundlag. Systemet finder og udvælger relevant materiale før der genereres et svar - så resultatet bliver mere præcist og kontrollerbart.
Kerneegenskaber
- Kildeforankrede svar - med tydeligt grundlag og referencer
- Adgangsstyring - svar og data efter rolle og rettighed
- Sporbarhed - logning, beslutningsspor og klare svar
- Kontrolleret svarlogik og specificerede instrukser
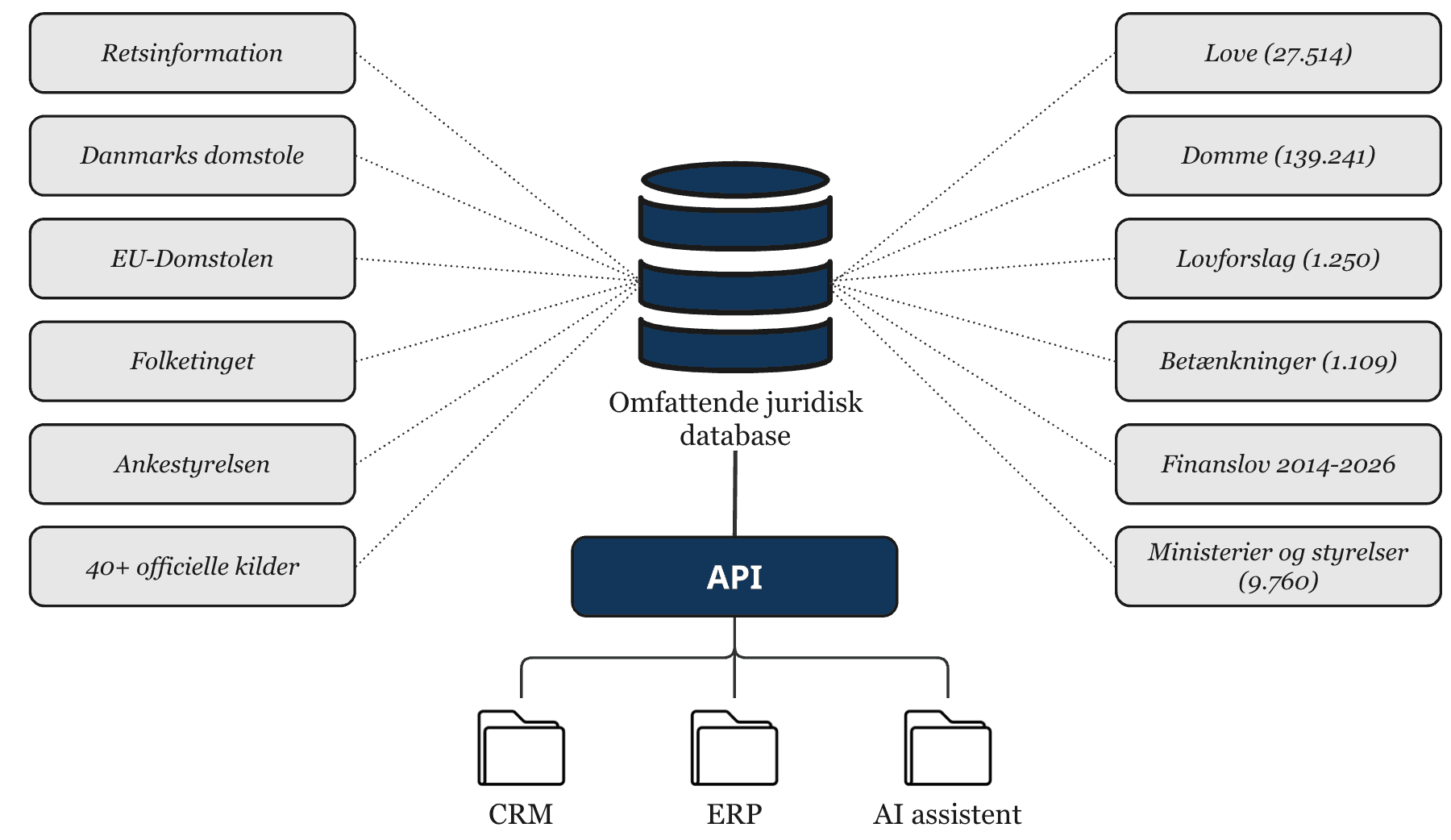
Omfattende juridisk database
Vi råder over en omfattende juridisk database med officielle kilder, versionssikre referencer og citationsklart output. Databasen kan indgå i løsninger, der tager udgangspunkt i dansk lovgivning og juridisk praksis.
- • 27.514 love (15.267 aktive, 12.247 historiske)
- • 139.241 domme og afgørelser
- • 1.250 nye lovforslag og 1.109 betænkninger
- • 40+ officielle kilder, herunder Retsinformation, Danmarks Domstole, EU-Domstolen og Folketinget
Integration med Microsoft - bygget oven på jeres eksisterende setup
Vores løsninger er designet til at arbejde direkte sammen med jeres Microsoft-miljø. I skal ikke skifte system, migrere data eller indføre nye loginstrukturer. Vi bygger et kontrolleret AI-lag oven på det, I allerede bruger.
Det betyder, at jeres dokumenter forbliver i SharePoint og OneDrive, jeres kommunikation i Teams og Outlook, og at adgang styres via Microsoft Entra ID. Vores platform fungerer som et styrings- og kontrollag mellem jeres data og AI-modellerne.
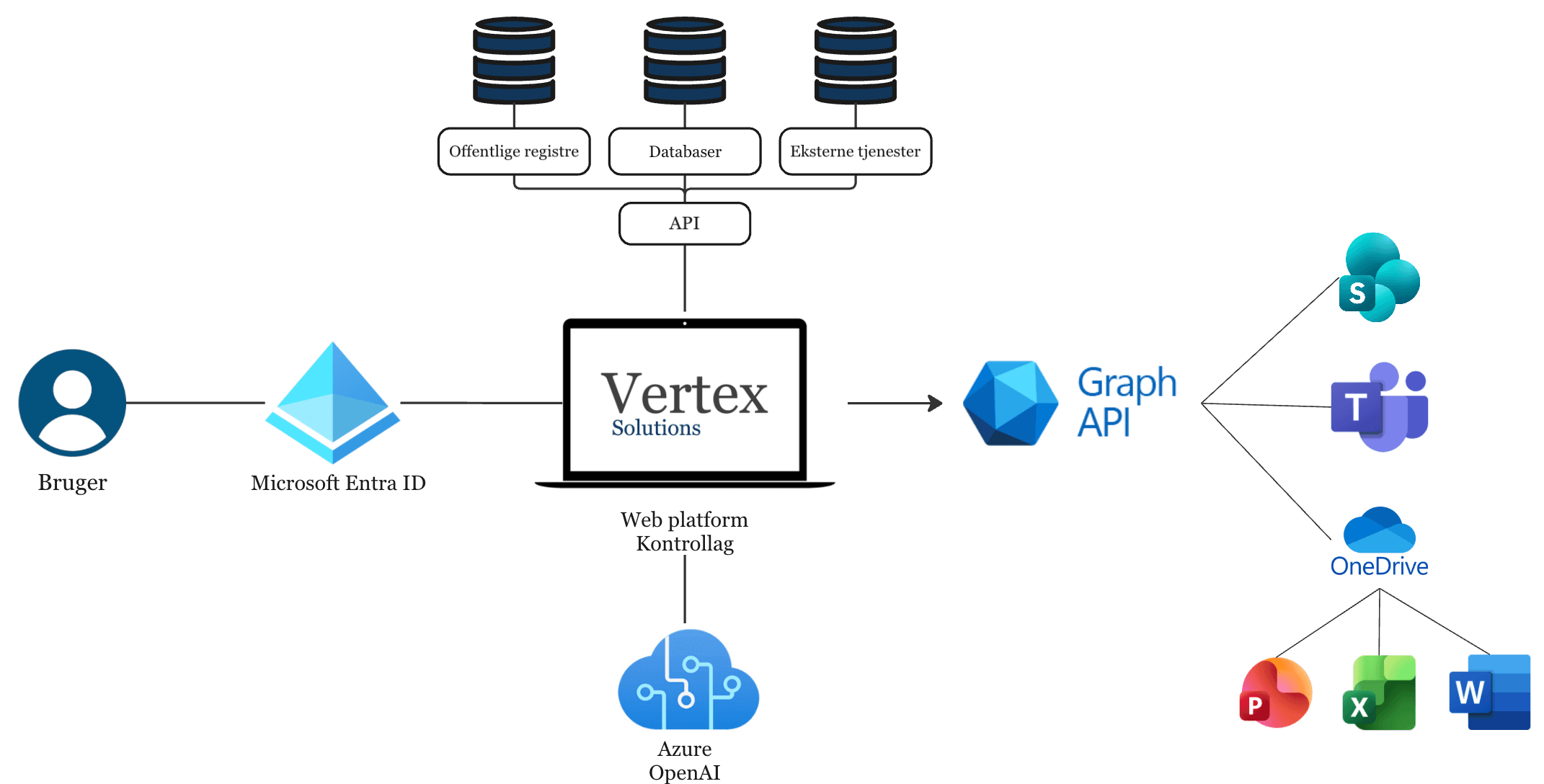
Sådan fungerer integrationen i praksis
- 01
Login via Microsoft Entra ID
Brugeren logger ind med virksomhedens eksisterende Microsoft-login. Rettigheder og roller følger med automatisk.
- 02
Adgang via Microsoft Graph
Platformen henter kun data, som brugeren allerede har adgang til i SharePoint, Teams eller OneDrive. Vi omgår ikke jeres rettighedsstruktur - vi respekterer den.
- 03
Kontrolleret behandling i platformen
Inden data sendes videre til AI, sker der en styring af:
- • Afgrænsning af datagrundlag
- • Rollebaseret adgang
- • Logning og sporbarhed
- • Eventuelle godkendelsespunkter
- 04
AI i jeres Azure-miljø
AI-kald sker via Azure OpenAI i jeres tenant. Data forlader ikke jeres Microsoft-setup, og modellen får kun den kontekst, som platformen eksplicit stiller til rådighed.
Hvad det betyder for jer
- • Ingen nyt login
- • Ingen flytning af dokumenter
- • Ingen parallelle systemer
- • Fuld respekt for jeres rettighedsstruktur
- • Sporbarhed og dokumentation ved brug af AI
Særligt relevant for organisationer med compliance-krav
For virksomheder med følsomme data eller regulatoriske krav er det afgørende, at AI ikke arbejder ukontrolleret i hele organisationens datamængde. Vores tilgang sikrer:
- • Afgrænset søgning i godkendte kilder
- • Tydelig svarlogik
- • Rollebaseret adgang
- • Dokumenterbar anvendelse
- • Mulighed for menneskelig godkendelse i kritiske processer
Det gør løsningen velegnet til eksempelvis advokatkontorer, offentlige myndigheder, revisionshuse og andre vidensorganisationer, hvor præcision og ansvarlighed er afgørende.
Kort sagt
Vi erstatter ikke jeres Microsoft-setup. Vi forstærker det.
Platformen samler identitet (Entra ID), data (SharePoint, OneDrive, Teams), integration (Graph API) og AI (Azure OpenAI) i en kontrolleret arkitektur, hvor I bevarer ejerskab, styring og overblik.